Appearance
Generalización cartográfica
La simplificación de polígonos en un SIG es un proceso fundamental de generalización cartográfica que busca reducir la complejidad de la geometría de una feature, eliminando vértices y suavizando contornos, pero manteniendo su forma esencial y características distintivas. Esta operación es crucial cuando se trabaja a diferentes escalas, ya que el nivel de detalle necesario para una representación a gran escala (por ejemplo, 1:5.000) resulta excesivo, redundante y visualmente confuso a escalas menores (como 1:100.000). El objetivo no es solo disminuir el peso del archivo y mejorar el rendimiento computacional, sino, sobre todo, garantizar la legibilidad del mapa, resaltando la información geográfica más relevante para el nivel de análisis o visualización requerido.
Existen diversos algoritmos matemáticos para llevar a cabo esta simplificación, cada uno con su lógica y resultados particulares. Uno de los más conocidos es el algoritmo de Douglas-Peucker, que identifica y elimina los vértices que menos contribuyen a la forma general del polígono, preservando aquellos que definen sus ángulos y cambios de dirección más significativos. Otros métodos, como el de suavizado (smoothing), aplican funciones para redondear las esquinas y crear contornos más orgánicos. La elección del algoritmo y el grado de tolerancia aplicado (es decir, la distancia máxima permitida entre la geometría original y la simplificada) son decisiones críticas que determinarán el equilibrio entre la simplificación y la fidelidad al elemento geográfico original.
Las aplicaciones de esta técnica son muy variadas. Por ejemplo, es indispensable en la creación de mapas base multiescala, donde un mismo dataset debe adaptarse dinámicamente a diferentes niveles de zoom. También se utiliza para simplificar límites administrativos complejos (como costas o fronteras naturales) para su publicación en mapas de pequeña escala, o para generalizar unidades de uso del suelo antes de un análisis territorial, agilizando los procesos de cálculo. Sin embargo, una simplificación excesiva o mal aplicada conlleva riesgos, como la pérdida de precisión crítica, la alteración de relaciones espaciales (por ejemplo, que dos polígonos adyacentes acaben solapándose o separándose) o la distorsión de la forma hasta hacerla irreconocible, lo que subraya la importancia de aplicar este proceso de manera consciente y controlada.
Error posicional
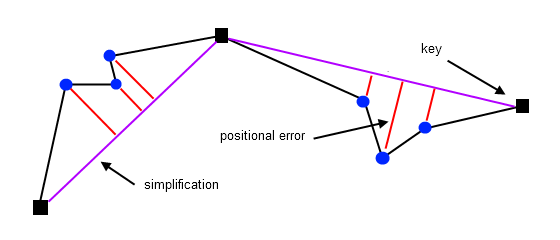
Los errores posicionales constituyen una métrica fundamental para evaluar la calidad de cualquier proceso de simplificación de líneas en SIG, ya que cuantifican la distorsión geométrica introducida al comparar la línea original con su versión simplificada. Estos errores se definen como la diferencia espacial entre la posición de los vértices de la polilínea original y la geometría resultante tras la simplificación. A mayor grado de simplificación (es decir, mayor reducción de vértices), generalmente se produce un incremento en la magnitud de estos errores, representando el inevitable trade-off entre compacidad de datos y fidelidad geométrica.
La medición típica de estos errores se realiza calculando la distancia perpendicular desde cada vértice de la línea original hasta el segmento correspondiente en la línea simplificada. Este enfoque captura efectivamente cuánto se ha desviado localmente la forma general como resultado del proceso de eliminación de vértices. En la práctica, se suelen emplear estadísticos como el error máximo, el error medio o la desviación estándar de estas distancias para caracterizar numéricamente el rendimiento del algoritmo de simplificación utilizado.
La distribución y magnitud de los errores posicionales varía significativamente entre diferentes algoritmos de simplificación, lo que permite establecer comparaciones objetivas sobre su eficacia. Algoritmos más avanzados como Douglas-Peucker o Visvalingam-Whyatt tienden a producir distribuciones de error más uniformes y valores máximos más contenidos en comparación con métodos más elementales como N-ésimo punto o Distancia Radial. Esta capacidad para minimizar consistentemente los errores posicionales mientras se alcanza un nivel dado de reducción de vértices es precisamente lo que distingue a los algoritmos de simplificación de mayor calidad en aplicaciones cartográficas y de análisis espacial.
Algoritmo del n-ésimo punto
El algoritmo "N-ésimo punto" (o "Punto Cada N") representa el enfoque más elemental para la simplificación de polilíneas, operando bajo un principio puramente aritmético sin considerar la geometría de la línea. Su funcionamiento se basa en seleccionar los vértices de la secuencia original siguiendo una progresión numérica predefinida: se conservan sistemáticamente el primer punto, el último punto y cada n-ésimo punto intermedio, descartando todos los demás sin ningún tipo de evaluación geométrica. Por ejemplo, con un valor de n=3, el algoritmo conservaría los puntos en las posiciones 1, 4, 7, así como el último punto de la secuencia, independientemente de su posición numérica.
La implementación de este algoritmo es notablemente sencilla y se realiza mediante un simple bucle que recorre el array de vértices, lo que resulta en una complejidad computacional lineal O(n). Esta característica lo convierte en uno de los métodos más rápidos disponibles, capaz de procesar grandes volúmenes de datos en tiempos mínimos. Su eficiencia se deriva directamente de la ausencia de cálculos geométricos complejos, comparaciones de distancias o evaluaciones de importancia de vértices, operaciones que sí están presentes en algoritmos más sofisticados como Douglas-Peucker o Visvalingam-Whyatt.
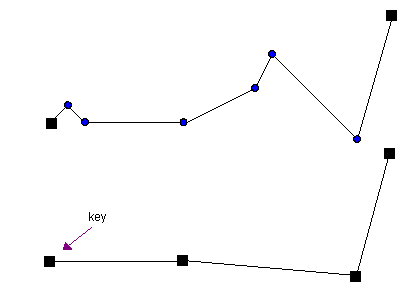
La principal limitación del algoritmo Nth Point radica en su completa indiferencia hacia las características geométricas de la línea original. Al basarse exclusivamente en el orden secuencial de los vértices, puede eliminar puntos críticos que definen curvas pronunciadas o ángulos agudos, mientras conserva puntos situados en tramos esencialmente rectos. Este comportamiento frecuentemente resulta en simplificaciones que distorsionan significativamente la forma original de la polilínea, produciendo representaciones que pueden perder sus rasgos característicos más importantes.
A pesar de sus deficiencias en la preservación geométrica, el algoritmo Nth Point encuentra aplicación en contextos donde la velocidad de procesamiento es prioritaria y la precisión geométrica es secundaria. Escenarios como la visualización preliminar de datos, la creación de vistas generales a escalas muy reducidas, o las aplicaciones en dispositivos con capacidad computacional limitada pueden beneficiarse de su extrema eficiencia. Sin embargo, para la mayoría de aplicaciones cartográficas que requieren fidelidad a la forma original, este método resulta insuficiente y debe complementarse con algoritmos más inteligentes de simplificación.
Algoritmo de distancia radial
El algoritmo de Distancia Radial es un método de simplificación de polilíneas que opera bajo un principio geométrico directo, eliminando vértices consecutivos que se encuentren agrupados dentro de una distancia umbral especificada. A diferencia de métodos más complejos que evalúan la contribución geométrica de cada punto, este algoritmo emplea un enfoque secuencial y "de fuerza bruta" que recorre la línea comparando distancias euclidianas entre vértices. Su objetivo principal es reducir la redundancia espacial eliminando puntos que están demasiado próximos entre sí, considerando que contribuyen mínimamente a la definición de la forma general de la línea.
El proceso comienza estableciendo los vértices extremos (el primero y el último) como puntos clave (keys) que siempre se preservan en la simplificación. Partiendo desde el primer punto clave, el algoritmo avanza secuencialmente a lo largo de la polilínea, calculando la distancia en línea recta desde este punto clave de referencia hasta cada vértice subsiguiente. Todos los vértices consecutivos cuya distancia radial al punto clave actual sea menor que la tolerancia especificada son inmediatamente descartados, ya que se consideran espacialmente redundantes.
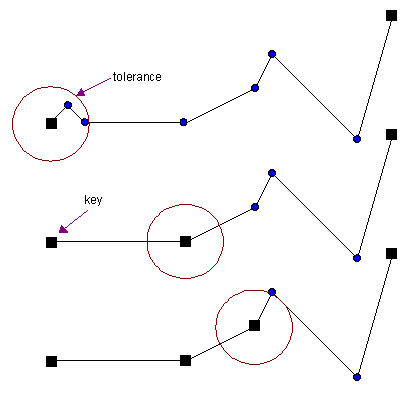
El momento crítico del algoritmo ocurre cuando se encuentra el primer vértice cuya distancia radial al punto clave de referencia supera el umbral de tolerancia. Este vértice es inmediatamente marcado como un nuevo punto clave y se convierte en la nueva referencia para las comparaciones subsiguientes. El algoritmo reinicia entonces el proceso de evaluación desde este nuevo punto clave, buscando el siguiente vértice que exceda la distancia tolerada. Este ciclo secuencial se repite de manera iterativa hasta alcanzar el último vértice de la polilínea, que como se estableció inicialmente, siempre se conserva como punto clave final.
La principal ventaja del algoritmo de Distancia Radial radica en su simplicidad conceptual y su eficiencia computacional, con una complejidad temporal lineal O(n) que lo hace adecuado para procesar grandes volúmenes de datos rápidamente. Sin embargo, su limitación fundamental es que puede preservar accidentalmente vértices que, aunque estén suficientemente lejos en términos de distancia radial, se encuentren en tramos esencialmente rectos, mientras podría eliminar puntos críticos en curvas cerradas si estos caen dentro del radio de tolerancia. Por esta razón, el algoritmo es más efectivo para eliminar clusters de vértices densos que para preservar fielmente la forma geométrica compleja de una línea.
Algoritmo de Distancia Perpendicular
El algoritmo de Distancia Perpendicular representa una evolución significativa respecto a métodos como el de Distancia Radial, ya que incorpora un criterio geométrico más sofisticado basado en la relación entre cada vértice y el segmento de línea que conecta sus vecinos adyacentes. En lugar de medir simples distancias punto-a-punto, este método calcula para cada vértice vi la distancia perpendicular al segmento S(vi-1, vi+1) que une sus dos vértices contiguos. Esta aproximación permite evaluar más efectivamente cuánto se desvía cada punto de la trayectoria lineal general, proporcionando un mejor criterio para identificar vértices redundantes en tramos esencialmente rectos de la polilínea.
El proceso se ejecuta de manera secuencial a lo largo de toda la línea, comenzando con los tres primeros vértices y avanzando de uno en uno. Para cada trío de vértices consecutivos, el algoritmo calcula la distancia perpendicular del vértice central al segmento que une sus dos véutices adyacentes. Si esta distancia es menor que la tolerancia especificada, el vértice central se considera redundante y es eliminado. Sin embargo, cuando la distancia excede la tolerancia, el vértice se marca como clave y se preserva en la simplificación. Este enfoque garantiza que se conserven los puntos que representan desviaciones significativas de la linealidad.
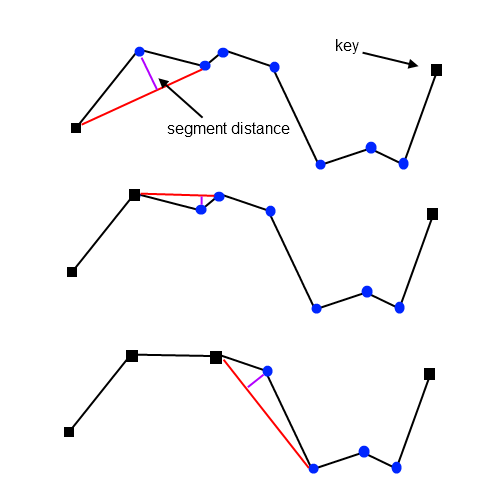
Una característica distintiva y limitante de este algoritmo es su restricción de salto después de cada eliminación. Cuando un vértice es eliminado, el algoritmo avanza dos posiciones en la polilínea en lugar de una, ya que el siguiente vértice inmediato se convierte en el nuevo punto medio de un trío diferente. Este mecanismo impone una limitación teórica máxima del 50% en la reducción de vértices para una sola pasada del algoritmo, ya que en el mejor de los casos solo se podrían eliminar los vértices en posiciones pares o impares, pero nunca dos consecutivos.
Para superar esta limitación y lograr mayores tasas de simplificación, el algoritmo requiere múltiples pasadas consecutivas sobre la polilínea. Cada pasada adicional puede eliminar más vértices que ahora se encuentran en tramos más rectos debido a las eliminaciones previas, acercándose progresivamente a la geometría simplificada deseada. Aunque este enfoque iterativo mejora los resultados, también incrementa el costo computacional. En comparación con métodos más avanzados como Douglas-Peucker, el algoritmo de Distancia Perpendicular sigue siendo relativamente eficiente pero menos efectivo para preservar características geométricas complejas con una sola ejecución.
Algoritmo de Reumann-Witkam
El algoritmo de Reumann-Witkam, desarrollado en 1974, representa uno de los primeros enfoques sistemáticos para la simplificación de líneas en el ámbito de la cartografía computacional. A diferencia de métodos recursivos como el de Douglas-Peucker, este algoritmo emplea una estrategia secuencial y procedimental que recuerda el funcionamiento de una ventana deslizante. Su objetivo fundamental es reducir el número de vértices de una polilínea manteniendo su trazo general, pero mediante un proceso más lineal y menos complejo computacionalmente que otros métodos contemporáneos. Esta característica lo convierte en una solución eficiente para aplicaciones donde el rendimiento es prioritario.
El mecanismo del algoritmo opera mediante una "ventana" de cuatro puntos consecutivos que se desplaza a lo largo de la línea. El proceso comienza fijando los dos primeros puntos (P0 y P1) y trazando una línea de referencia entre ellos. Luego, se establece un "corredor" o banda de tolerancia perpendicular a esta línea, con una anchura definida por el usuario. El algoritmo examina entonces la posición del tercer punto (P2) con respecto a este corredor: si dicho punto se encuentra dentro de la banda de tolerancia, significa que su contribución a la forma general es mínima y puede ser eliminado, tras lo cual la ventana se desplaza para evaluar el siguiente punto.
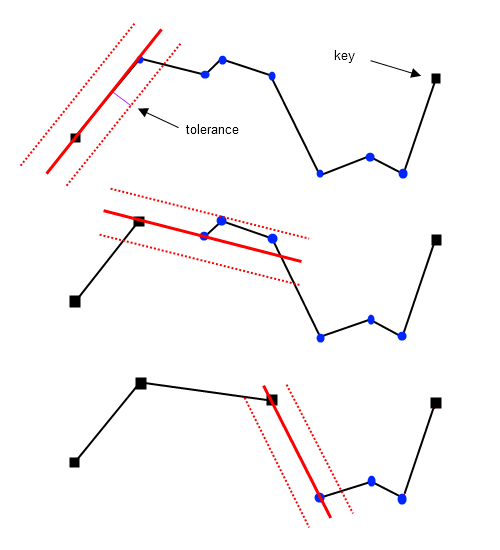
Sin embargo, cuando un punto se sitúa fuera del corredor de tolerancia, el algoritmo interpreta que ha identificado un vértice significativo que debe preservarse. En este caso, el punto anterior a aquel que ha fallado la verificación (es decir, el último punto que estaba dentro del corredor) se marca para su conservación, y la ventana se reconfigura tomando este punto conservado como nueva referencia inicial. Este proceso de evaluación y desplazamiento continúa secuencialmente hasta haber recorrido toda la línea, produciendo una geometría simplificada donde solo permanecen los puntos considerados esenciales según el criterio del corredor de tolerancia.
La principal ventaja del algoritmo de Reumann-Witkam radica en su simplicidad conceptual y su eficiencia computacional, al evitar los procesos recursivos que caracterizan a otros métodos. No obstante, esta misma simplicidad constituye su limitación más notable: al basarse únicamente en una evaluación local de puntos consecutivos, puede fallar en reconocer características geométricas globales de la línea, lo que en algunos casos resulta en una preservación subóptima de la forma original. A pesar de esta limitación, su elegante implementación lo mantiene como una opción válida en contextos donde se privilegia la velocidad de procesamiento sobre la máxima fidelidad cartográfica.
Algoritmo de Opheim
El algoritmo de Opheim representa una refinación importante del método de Reumann-Witkam al introducir un área de búsqueda restringida mediante el uso de dos tolerancias espaciales: una distancia mínima y una distancia máxima. Esta aproximación de doble criterio permite un control más preciso sobre el proceso de simplificación, combatiendo una limitación fundamental de su predecesor: la tendencia a eliminar demasiados vértices en regiones de alta densidad. El algoritmo mantiene la eficiencia computacional lineal O(n) característica de los métodos secuenciales, pero produce resultados más balanceados al proteger los vértices muy cercanos al punto clave actual de ser eliminados prematuramente.
El proceso comienza con el primer vértice marcado como punto clave (vkey). Para cada vértice sucesivo vi, el algoritmo primero verifica su distancia radial respecto a vkey. Se identifica el último vértice que se encuentra dentro de la tolerancia mínima, el cual se utiliza para definir un rayo direccional R(vkey, vi). Este rayo establece la dirección de referencia para las evaluaciones posteriores. Si ningún vértice cae dentro de la tolerancia mínima, el rayo se define simplemente usando el vértice inmediatamente siguiente a vkey. Esta etapa inicial asegura que los vértices muy próximos al punto clave actual no sean eliminados indiscriminadamente.
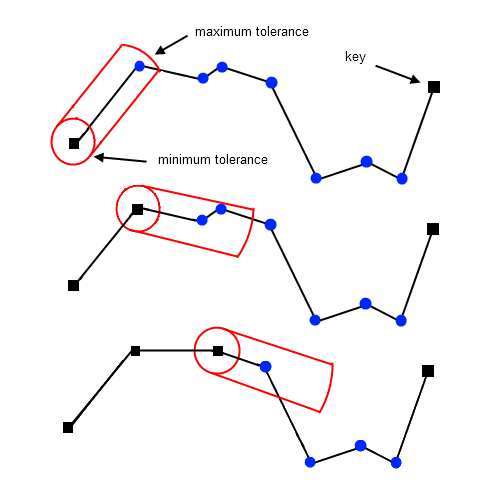
Una vez establecido el rayo director, el algoritmo evalúa los vértices subsiguientes vj más allá de vi, calculando ahora su distancia perpendicular al rayo R. El proceso de búsqueda de un nuevo punto clave se activa cuando se cumple una de dos condiciones: cuando la distancia perpendicular de vj al rayo R excede la tolerancia mínima, o cuando la distancia radial entre vj y vkey supera la tolerancia máxima. Al alcanzar cualquiera de estos límites, el vértice inmediatamente anterior (vj-1) es designado como el nuevo punto clave, y el proceso se reinicia desde esta nueva posición de referencia.
La principal ventaja del algoritmo de Opheim reside en su capacidad para preservar detalles locales en regiones de alta densidad de vértices mientras aún elimina eficientemente puntos redundantes en tramos más largos. Al establecer una zona de exclusión mínima, protege la geometría local inmediata al punto clave actual; mientras que la tolerancia máxima previene que el algoritmo busque demasiado lejos a lo largo de la polilínea. Este control dual produce simplificaciones más fieles al carácter original de la línea que el método Reumann-Witkam, particularmente en datasets con densidad de vértices variable, aunque a costa de requerir la calibración de dos parámetros en lugar de uno.
Algoritmo de Douglas-Peucker
El algoritmo de Douglas-Peucker, también conocido como algoritmo de simplificación de Ramer-Douglas-Peucker, es un método fundamental en la generalización de líneas y polígonos dentro de los Sistemas de Información Geográfica (SIG). Su objetivo principal es reducir significativamente el número de vértices que componen una geometría lineal, eliminando aquellos que son redundantes, mientras se preserva de manera fiel la forma esencial de la línea o el contorno original. A diferencia de otros métodos que pueden simplemente eliminar vértices a intervalos regulares, este algoritmo es inteligente, ya que evalúa la contribución geométrica de cada punto para decidir si se conserva o se descarta, garantizando que la versión simplificada sea una representación precisa de la original dentro de un margen de error predefinido.
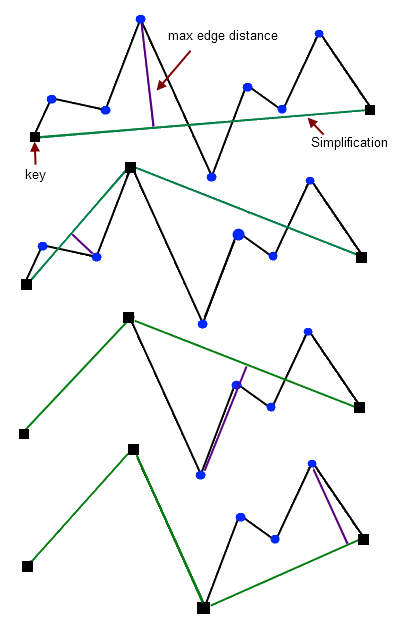
El funcionamiento del algoritmo se basa en un principio recursivo y una tolerancia espacial (épsilon) elegida por el usuario. El proceso comienza seleccionando los dos puntos extremos de la línea (inicio y fin) y trazando una línea recta entre ellos. A continuación, se calcula la distancia perpendicular de todos los puntos intermedios a este segmento de línea recta. El punto que tenga la mayor distancia a este segmento es identificado. Si esta distancia máxima es mayor que la tolerancia épsilon, este punto se marca como significativo y debe conservarse. Este punto divide entonces la línea original en dos sub-líneas, y el mismo proceso se aplica recursivamente a cada uno de estos nuevos tramos.
La recursividad es la clave del algoritmo. Cada vez que un punto es retenido por exceder la tolerancia, se convierte en un nuevo ancla que segmenta la línea. El proceso continúa dividiendo los segmentos resultantes y evaluando los puntos intermedios en cada uno, hasta que, para todos los sub-segmentos creados, la distancia máxima de cualquier punto intermedio a la línea que une sus extremos sea menor que el valor épsilon. Cuando se alcanza esta condición en todos los tramos, el proceso se detiene. Los puntos que han sido marcados para conservarse a lo largo de todas las iteraciones son los que formarán la línea simplificada final, conectados en el mismo orden en que aparecían originalmente.
La principal ventaja del algoritmo de Douglas-Peucker es su capacidad para retener los puntos que definen los rasgos característicos de la línea (como picos o curvas pronunciadas) y descartar aquellos que se encuentran en tramos prácticamente rectos. Sin embargo, su resultado depende críticamente de la elección de la tolerancia épsilon: un valor muy pequeño producirá una línea casi idéntica a la original, mientras que un valor muy grande generará una simplificación excesiva que puede distorsionar la forma e incluso alterar relaciones espaciales cruciales. A pesar de esta sensibilidad, su eficiencia y resultados intuitivos lo han consolidado como uno de los métodos más populares y ampliamente implementados en software SIG para la generalización cartográfica.
Algoritmo de Lang
El algoritmo de simplificación desarrollado por Theo Lang en 1969, aunque publicado significativamente más tarde, introduce un enfoque innovador basado en el concepto de "banda de tolerancia" o "corredor". A diferencia del método recursivo de Douglas-Peucker, el algoritmo de Lang utiliza un enfoque secuencial que busca hacia adelante desde un punto de partida, creando un área de tolerancia alrededor del segmento inicial. Esta banda se define como la región delimitada por dos líneas paralelas equidistantes del segmento base, donde la distancia está determinada por el valor de tolerancia elegido por el usuario. El algoritmo procesa sistemáticamente los vértices subsiguientes para determinar cuántos de ellos pueden ser eliminados mientras se mantienen dentro de este corredor virtual.
El proceso comienza seleccionando un punto de partida (normalmente el primer vértice del polígono) y estableciendo un segmento inicial hacia el siguiente punto. A continuación, se traza la banda de tolerancia perpendicular a este segmento base, con una anchura igual al doble del valor de tolerancia especificado. El algoritmo entonces examina los puntos sucesivos en la secuencia, verificando si cada uno de ellos permanece dentro de los límites de esta banda. Mientras los puntos consecutivos se mantengan dentro del corredor, el algoritmo continúa expandiendo virtualmente el segmento bajo evaluación y descartando los puntos intermedios que no violan la restricción espacial.
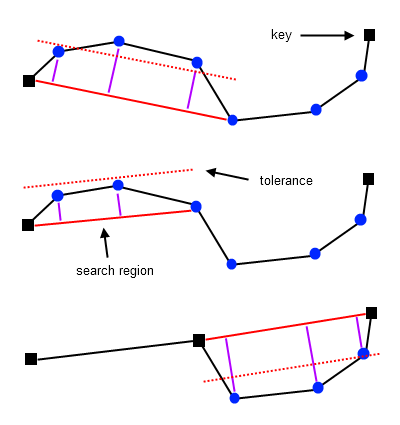
El momento crítico del algoritmo ocurre cuando se encuentra un vértice que se sitúa fuera de los límites de la banda de tolerancia. Cuando se detecta tal punto, el algoritmo retrocede al vértice inmediatamente anterior que todavía estaba dentro del corredor y lo marca para su conservación en la geometría simplificada. Este punto conservado se convierte entonces en el nuevo punto de inicio, y el proceso se reinicia: se establece un nuevo segmento base y una nueva banda de tolerancia hacia los puntos siguientes. Esta iteración continúa hasta que se han procesado todos los vértices del polígono original.
La principal ventaja del algoritmo de Lang reside en su capacidad para manejar eficientemente curvas suaves y largas, donde puede eliminar múltiples vértices en una sola operación, a diferencia de métodos más conservadores. Sin embargo, su rendimiento puede verse afectado por la presencia de vértices aislados que se salen abruptamente del corredor, lo que fuerza la creación de múltiples segmentos cortos. A pesar de ser menos conocido que el algoritmo de Douglas-Peucker, el método de Lang representa una contribución significativa a la cartografía computacional, ofreciendo un enfoque alternativo que equilibra eficiencia con preservación de la forma general en procesos de simplificación geométrica.
Algoritmo de Visvalingam-Whyatt
El algoritmo de Visvalingam-Whyatt, publicado en 1993, representa un cambio de paradigma fundamental en la simplificación de líneas al introducir un enfoque bottom-up (de abajo hacia arriba) basado en la importancia geométrica local de cada vértice. A diferencia de los métodos top-down como Douglas-Peucker que parten de la forma global, este algoritmo se centra en evaluar y eliminar progresivamente los puntos menos significativos. La premisa central es que la importancia de un vértice puede medirse por el área del triángulo formado por éste y sus dos vértices adyacentes inmediatos, lo que se conoce como su "área triangular efectiva". Esta métrica cuantifica cuánto contribuye cada punto a la geometría general de la línea.
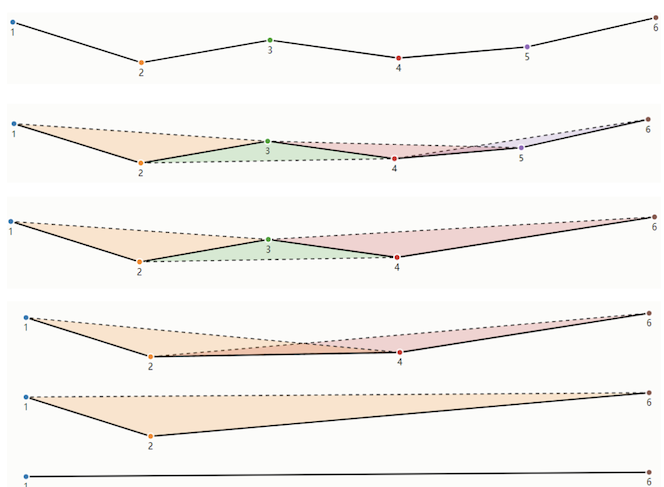
El proceso comienza calculando el área triangular efectiva para todos los vértices internos de la línea (excluyendo los puntos extremos). Cada vértice se considera junto con su predecesor y sucesor inmediato, formando un triángulo cuya área representa visualmente la prominencia de ese punto en el contorno. Una vez calculadas todas las áreas, el algoritmo identifica el vértice con el área triangular más pequeña, ya que representa la desviación menos significativa de una línea recta entre sus vecinos. Este vértice es eliminado de la geometría, y la línea se reconecta directamente entre sus puntos adyacentes, realizando así la primera simplificación.
Tras cada eliminación, el algoritmo actualiza dinámicamente las áreas triangulares efectivas de los vértices vecinos al punto removido. Esta recalificación es crucial, ya que la eliminación de un vértice altera el contexto geométrico de sus puntos adyacentes, cambiando potencialmente su importancia relativa. El proceso se repite iterativamente: calcular áreas, identificar y eliminar el vértice con el área más pequeña, y actualizar los valores de los vecinos. Esta eliminación progresiva continúa hasta que se alcanza un criterio de parada, que puede ser un número deseado de vértices finales o un umbral mínimo de área triangular.
La principal ventaja del algoritmo de Visvalingam-Whyatt es su capacidad para producir resultados visualmente coherentes, ya que elimina sistemáticamente las variaciones más suaves y preserva naturalmente los picos y curvas pronunciadas que tienen áreas triangulares grandes. Además, al recalcular las áreas después de cada eliminación, el algoritmo se adapta inteligentemente a los cambios en la geometría. Sin embargo, su naturaleza iterativa lo hace computacionalmente más demandante que otros métodos, especialmente para líneas con miles de vértices. A pesar de esto, su lógica intuitiva y excelentes resultados lo han convertido en la base de herramientas de simplificación modernas en plataformas como Mapshaper y bibliotecas GIS avanzadas.